Mediators
Urban Rezoning Board Game with Multi-Agent Learning

Introduction
In urban planning, the hardest step is to reach consensus, driven by endless negotiations and exchanges of interests between stakeholders. The process often involves extensive negotiations, trade-offs, and compromises that can lead to inefficiencies and inequities. As a prototype, the project introduces a customized digital "board game", which offers a minimal abstraction of real-world scenarios by abstracting core stakeholder personas and modeling their roles and interactions with each other and the environment. With Multi-Agent Reinforcement Learning, the project evaluates different algorithms that trained on different levels of shared information, and their performance on helping the agent learn to collaborate and maximize their self-interests under distinct objectives, strategies, and constraints. The vision of this project is to shift the traditionally gatop-down urbanization process into an AI-augmented, participatory approach, empowering diverse voices to be captured with player's reward functions and can reflect the values to the other players and the environment.
Player and Actions
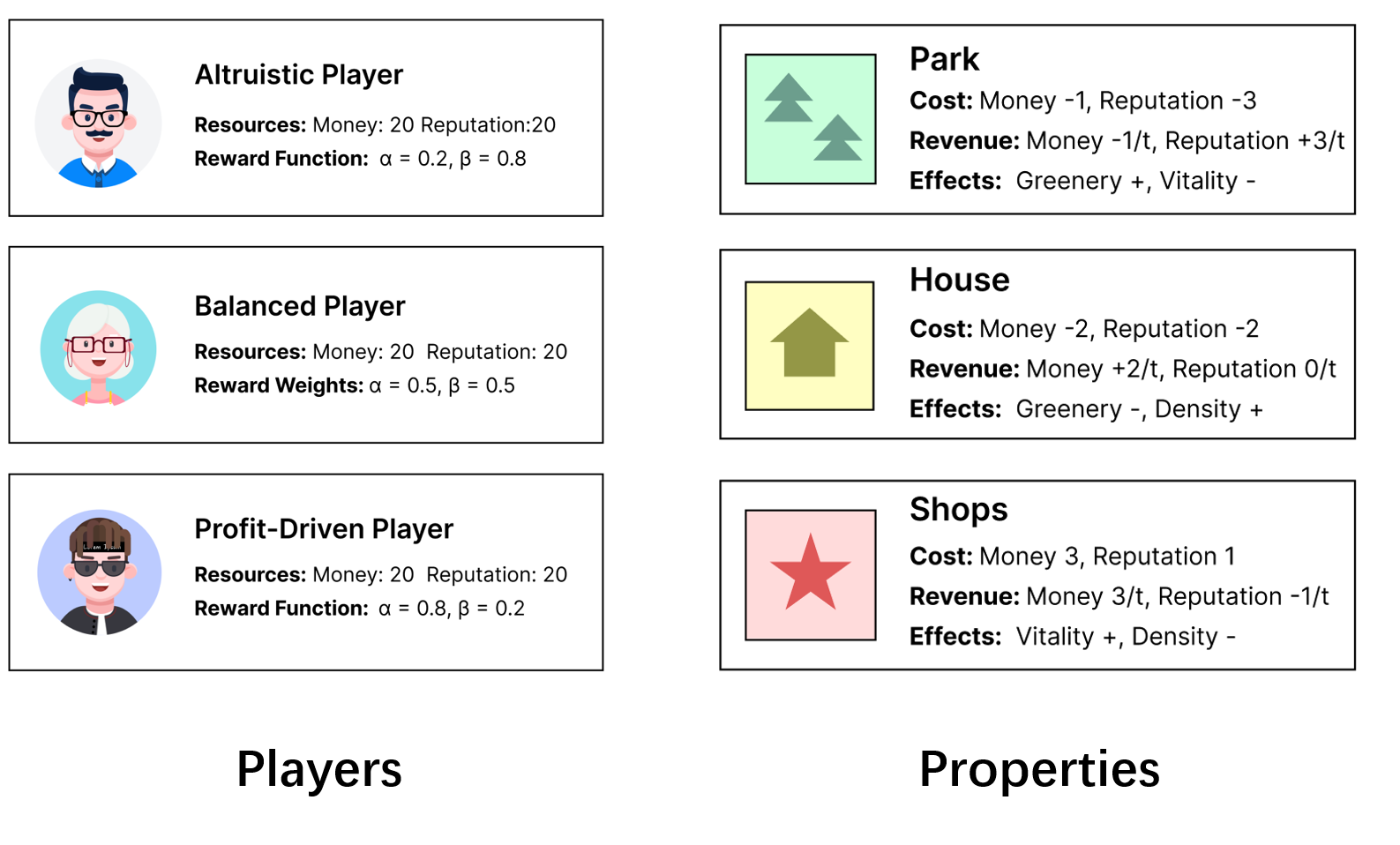
Minimal Player and Action Setup
Players take actions sequentially in each turn. A player can construct a building on an available cell or choose to skip (no-op action). In total, there are (4 \times 4 \times 3 + 1) available actions for each player.
Each building type requires resources (money and reputation) to build, triggering both immediate changes on the map and long-term returns. For instance, parks improve greenery but reduce vitality. In each sequential turn, the park will charge the builder's money as a maintenance fee but will increase the builder's reputation. These trade-offs force players to carefully consider (learn) the short-term and long-term impacts of their actions, both on their own rewards and on the shared environment.
Game Loop
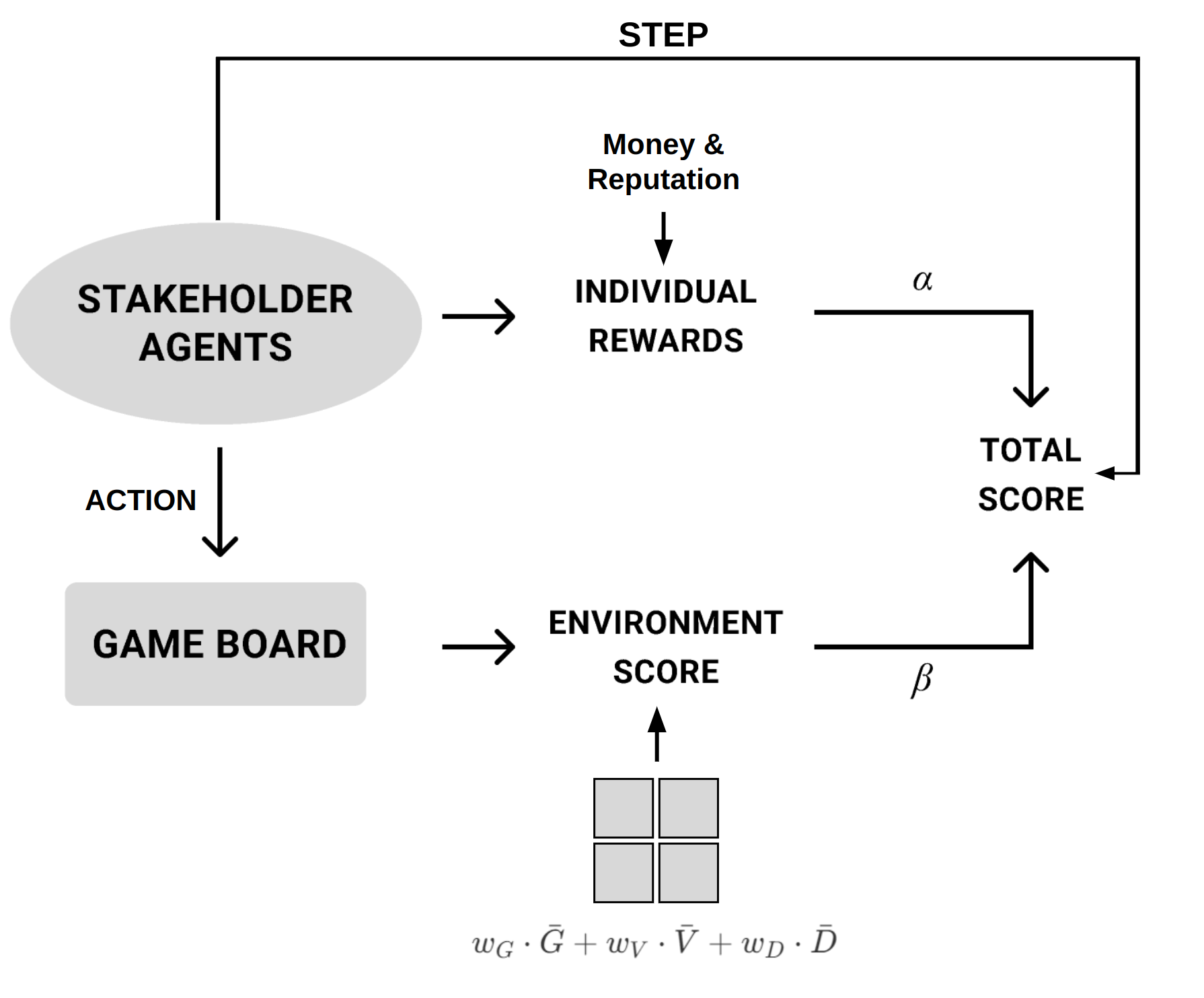
Game Loop
The game loop displayed in Figure 1 shows the iterative process where stakeholder agents take actions that modify the game board. The player acts sequentially in turns, and their actions update both individual rewards (money and reputation) and an environment score. The individual rewards ((\alpha)) and the environment score ((\beta)) are combined into a total score, which reflects the balance between agents' personal objectives and the shared environmental impact.
Observation Space

Observation Space for Agents
The observation space evolves dynamically during each turn as agents take actions. The diagram in Figure 1 illustrates the changes in the observation space at each turn. Cells with values that change due to the agent's actions are highlighted in green for increases, red for decreases, and blue for neutral changes, such as updating the builder value.
In the actual implementation, we define the observation space as a collection of matrices, including the status of the grid, the player's current resources, and the distribution of builders and building types on the map. Before being used in the training algorithm, the grid is flattened. This observation space provides all the necessary information for Player 1's decision-making process in the current turn.
Each sub-matrix corresponds to a 4×4 grid, with each cell containing indices for Greenery (G), Vitality (V), and Density (D). In the builder location matrix, 0, 1, and 2 represent the builders (players) assigned to each cell, while -1 indicates unoccupied cells. In the building types matrix, numbers correspond to different building types (0 = Park, 1 = House, 2 = Shop, and -1 indicates no building).
System Structure
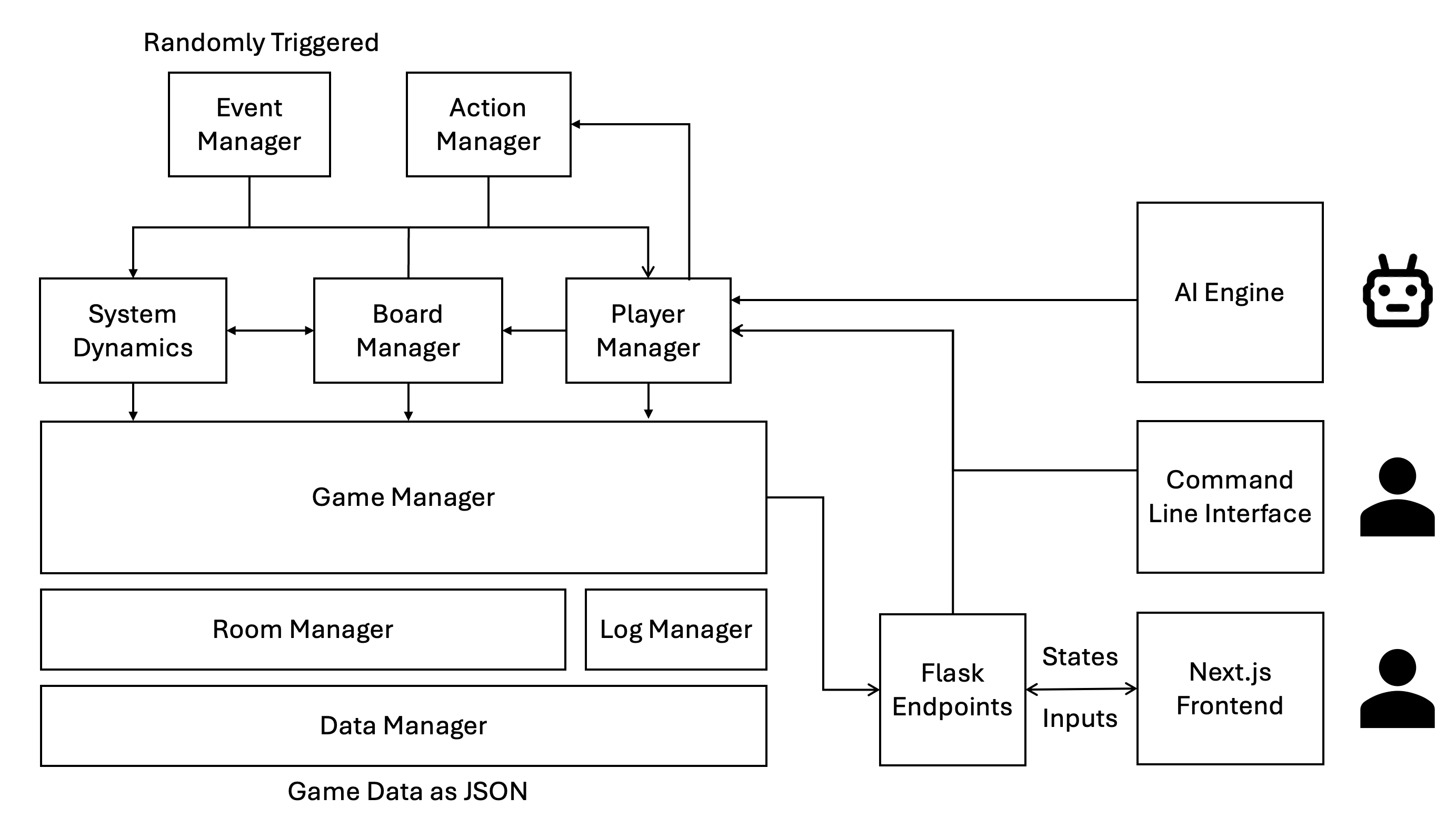
Game Theory Analysis
Our game can be seen as a repeated non-zero-sum Markov game
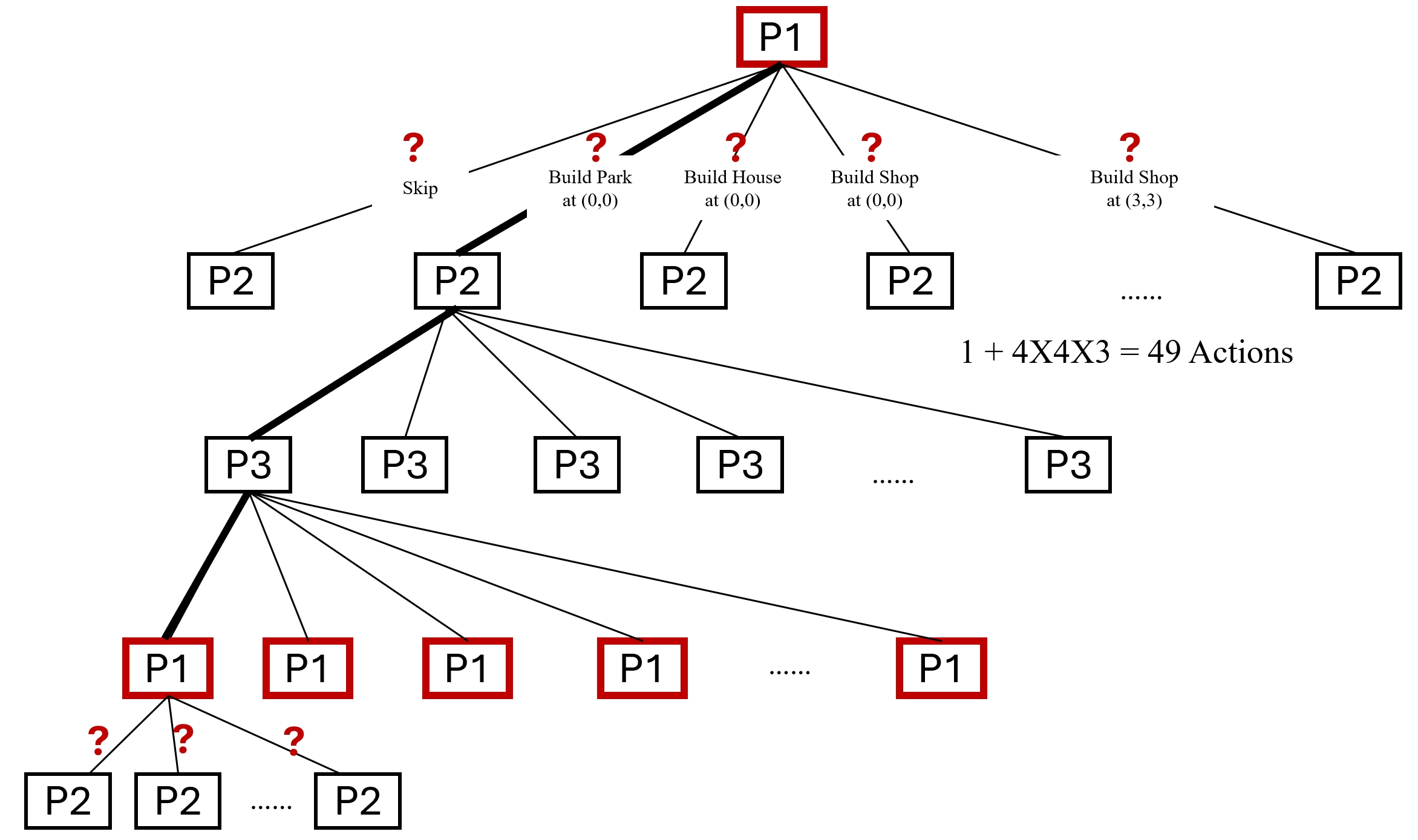
Tree Form Decision Process (From the Perspective of Player 1)
Figure 6 illustrates the tree form decision process from the perspective of Player 1. The player must be trained to develop a strategy for making decisions based on environmental observations.
Due to the non-zero-sum nature of the game, players can simultaneously improve their outcomes by coordinating actions that raise the overall environment score. This means the solution space includes equilibria that yield mutually beneficial outcomes.
However, due to the complexity of the game, finding a Nash equilibrium analytically is difficult. Instead, a relaxed equilibrium, Coarse Correlated Equilibrium (CCE), may be found using learning algorithms if they converge. The converging point represents a state where no player wishes to deviate, given the distribution of other players’ strategies.
If the parameters are constructed properly, we may find a Pareto optimal solution for multiple players, where no player can improve their outcome without making another player worse off. In our game, cooperative strategies that improve the environment could lead to Pareto improvements. However, interest-driven players may deviate from collaborative strategies and disrupt the equilibrium.
Training and Evaluation
We conduct our experiments to train the agents using different algorithms, targeting 1,000,000 iterations. Given the dramatic differences between the algorithms, some of them were not able to complete within 40 hours. We trained the models on a server with a 16-core CPU and an RTX 4090 GPU. Some algorithms were executed on the GPU using CUDA.
We set two learning goals:
- Maximize the common reward (the average of the individual rewards).
- Maximize the individual rewards.
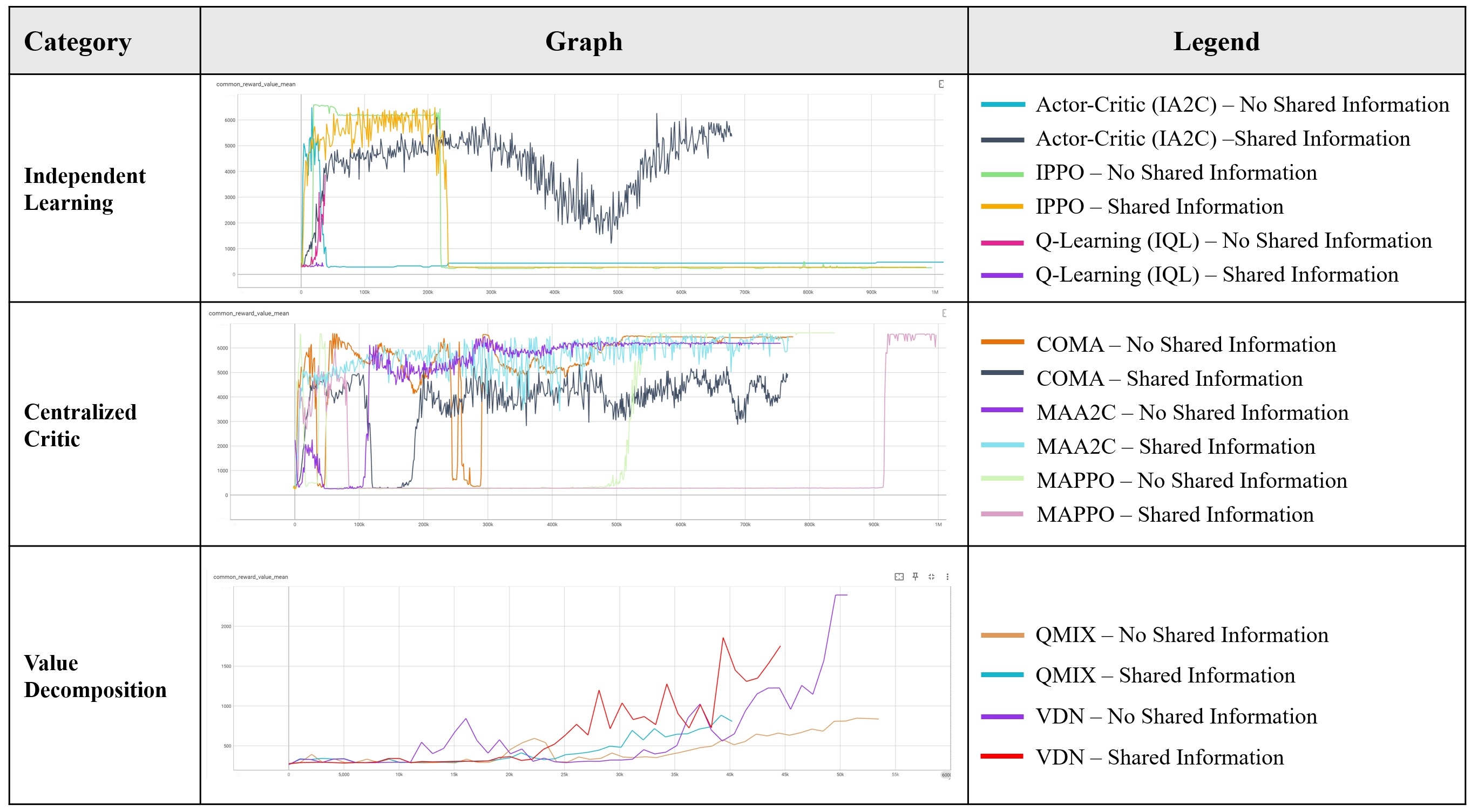
Test Result - Maximize Common Reward
We first set the objective to maximize the common reward. When training the agents individually, we encountered huge oscillations. Algorithms like PPO and A2C often fell into a suboptimal state despite achieving high-reward phases. This behavior may be due to the fact that each agent treats others as part of an uncertain environment. Without access to others’ policies or observations, the learning signal becomes noisy and non-stationary, causing fluctuations in the reward curves.
Using the centralized critic method, the MAA2C algorithm performed the best, stabilizing around the optimal strategy. However, COMA and MAPPO were unstable during training, often falling into suboptimal states. Despite this, MAPPO managed to recover from suboptimal states, eventually increasing its reward.
The performance of MAA2C suggests that combining centralized training with shared information is effective in fostering mutual understanding and facilitating collaborative policies. In contrast, COMA and MAPPO demonstrated lower stability. This may be due to COMA’s reliance on counterfactual baselines, which work well in simpler scenarios, but in complex dynamics with a rich action space, it struggles to provide consistently improving signals.
For the Value Decomposition method, the reward grew slowly and was unstable. These algorithms attempt to learn a factorization of the global value function into individual components, which can be powerful in purely cooperative tasks. However, they performed poorly in our game, which involves competition between players.
Key Observations:
- Training with shared information allows agents to learn faster than without it, as they can coordinate more effectively.
- However, shared information also introduces more oscillation during training, possibly due to policy changes affecting learning, leading agents to fall into passive action traps (e.g., skipping turns).
- The strong performance of MAA2C with shared information suggests that when paired with a suitable algorithm, shared information significantly enhances long-term cooperative outcomes.