A Gamified Framework for Conflict-Driven Design
Multi-Agent Learning for Collective Decision-Making in Urban Planning
INTRODUCTION
In many design projects, one of the most challenging steps is reaching consensus, often shaped by negotiations and exchanges of interests among stakeholders. Our research introduces a customized digital "board game" that provides a minimal abstraction of the real-world city-building process by modeling core stakeholder personas, their roles, and interactions. Within this environment, we apply multi-agent reinforcement learning (MARL) to train AI agents to develop strategies for resource allocation under competing objectives. The trained models are then used to simulate planning processes in conflict-driven scenarios, offering insights into negotiation dynamics and stakeholder trade-offs. Furthermore, we present a human-in-the-loop interface that enables participants to visualize the simulation process and interact with AI agents, supporting a deeper understanding of planning dynamics while offering valuable insights into real-world conundrums.
Related Work
Board games have long been established as participatory tools. In the board game community, city building is an important genre, exemplified by games such as Bay Area Regional Planner, Small Cities, and Suburbia. Serious games are also widely used in academic research (Poplin, 2012; Prasad et al., 2021), where interactive interfaces have emerged for participatory planning, bridging the gap between algorithmic optimization and public participation, such as CityScope (Alonso et al., 2018).
Game theory provides theoretical foundations in modeling and evaluating the decision process and equilibria. Prior studies have applied it to model land-use negotiations among stakeholders (Liu et al., 2016), and collective decision-making processes for urban planning (Abolhasani et al., 2022). These studies provide theoretical foundations for analyzing interdependent decision-making in urban contexts.
Agent-based models (ABMs) have been widely used to capture population-level interactions and emergent behaviors in urban environments (Batty, 2005; Bijandi et al., 2021; Crooks et al., 2008). However, ABM agents are often built on simplified rule-based behaviors that have limited capabilities for making complex decisions.
Multi-agent reinforcement learning (MARL) offers a computational extension to these models, where agents learn strategies through self-play and train neural networks based on interactions in a customized environment. Kaviari et al. (2019) and Qian et al. (2023) used game-theoretic MARL frameworks to simulate urban growth and participatory planning under competing stakeholder interests. Pushing further, Cicero (Meta AI, 2022) demonstrated how MARL integrated with natural language processing enables agents to master more complex games.
Our research contributes to the realm by proposing a scalable methodology that abstracts the urban decision-making process via games and uses a customized environment to perform efficient MARL training. Agents are trained and evaluated under different reward matrices to study how value propositions affect strategy cooperation under real-world contexts. The workflow contributes to the emerging field of multi-agent learning and computational urban planning by offering real-world use cases and a gamified testbed for collaborative decision-making. Our vision of this project is to shift the traditionally top-down urbanization process into an AI-augmented, participatory approach, empowering diverse voices to be captured with players' reward functions and trained under interpretable approaches.
METHODS
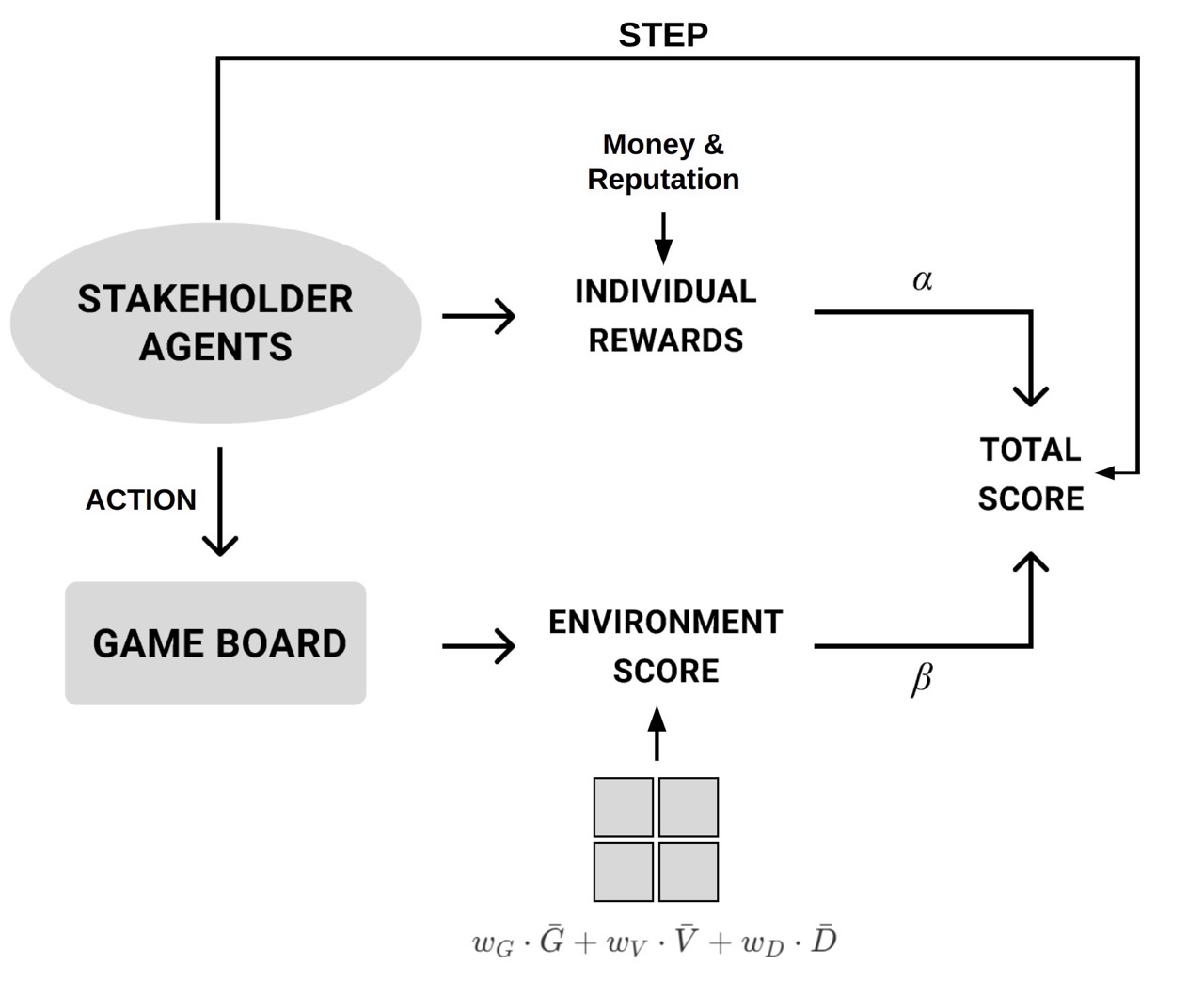
Our method consists of three tightly coupled components. First, we introduce a scalable game environment that simulates core stakeholder interactions. It serves both as a participatory abstraction for modeling real-world planning dynamics and as a testbed for agents to act and learn. Then, we introduce a multi-agent learning workflow, where agents learn adaptive strategies under different value matrices in the game environment. Lastly, we present a digital human interface to allow humans to observe the game status and interact with agents during the decision process.
Environment
Our goal is to define a game environment that captures the complexity of collective decision-making while remaining feasible for agent training. We found that a board game with discrete actions fits this purpose. A central design consideration is the level of abstraction: the game should preserve the key dynamics involved in the design process and balance between stakeholders. For example, when simulating investment-reward dynamics, a critical decision is whether players should continuously receive rewards from their investments over subsequent turns—a factor that directly shapes agents' perspectives on long-term benefits. These nuanced design decisions require fine-tuning to balance between reflecting real-world trade-offs and enabling agents to learn long-term strategies within computational constraints.
The game map consists of a configurable M × N grid. Each cell has key parameters that represent the environmental, economic, and social aspects of urban development. These parameters are initialized based on the original terrain and any pre-existing projects, and are dynamically updated each round according to the buildings placed on the board and their effects on both the selected and adjacent cells. The overall environment score is calculated as the average of all indices across the grid. During each turn, players act sequentially, choosing either to construct a building on an available cell or to skip their turn.
Agents in our framework represent stakeholders whose actions shape the environment. Since stakeholders often pursue diverse and sometimes conflicting objectives, we model their priorities using value matrices, where each player's reward is parameterized by weights that balance self-interest against map parameters representing site conditions and resilience. To capture this diversity, we define an integrated reward function that combines individual resource gains with the collective impacts encoded in the game map parameters.
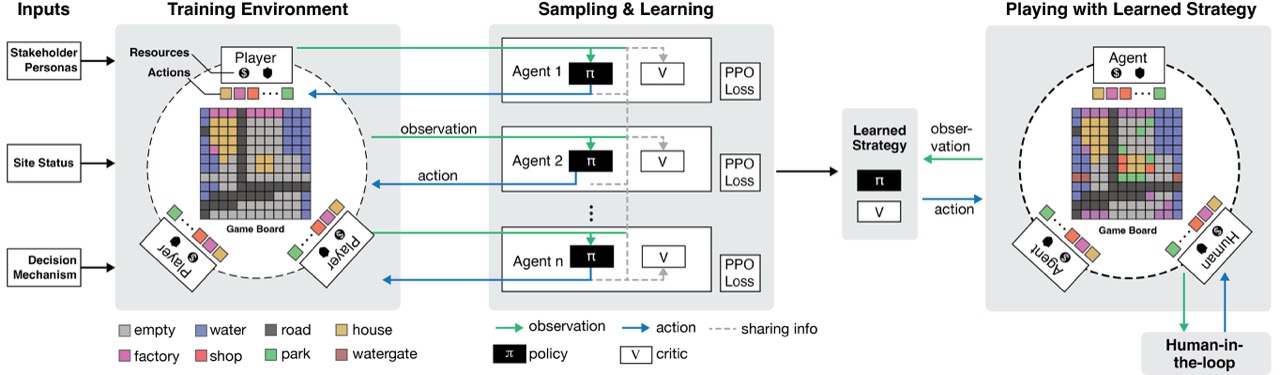
Multi-Agent Learning
Unlike well-studied games like Poker, Tic-tac-Toe, or Rock-Paper-Scissors, which are governed by clear rules and often exhibit zero-sum properties, the proposed game environment is non-zero-sum in nature. That is, stakeholders typically have conflicting objectives, but their actions can also generate shared benefits or collective challenges. This makes it challenging for us to use the properties and theories of zero-sum games to analyze the expected outcome of the game.
The agents will need to be trained to learn a strategy to make decisions under the observation from the environment. Due to the non-zero-sum nature, the players can jointly improve their outcomes by coordinating actions that raise the overall environment score. As a result, the solution space includes equilibria that are not strictly competitive, but rather mutually beneficial. Instead, we consider a more tractable equilibrium concept—Coarse Correlated Equilibrium (CCE). A CCE represents a strategy distribution from which no agent has an incentive to unilaterally deviate, given the correlation structure of others' strategies. It can be approached through learning-based methods. We may find a Pareto optimum for multiple players, where no player can improve their outcome without making another player worse off. In our game, cooperative strategies that improve the environment could lead to Pareto improvements. Less cooperative players, such as interest-driven player may deviate from collaborative strategies and break the equilibrium.
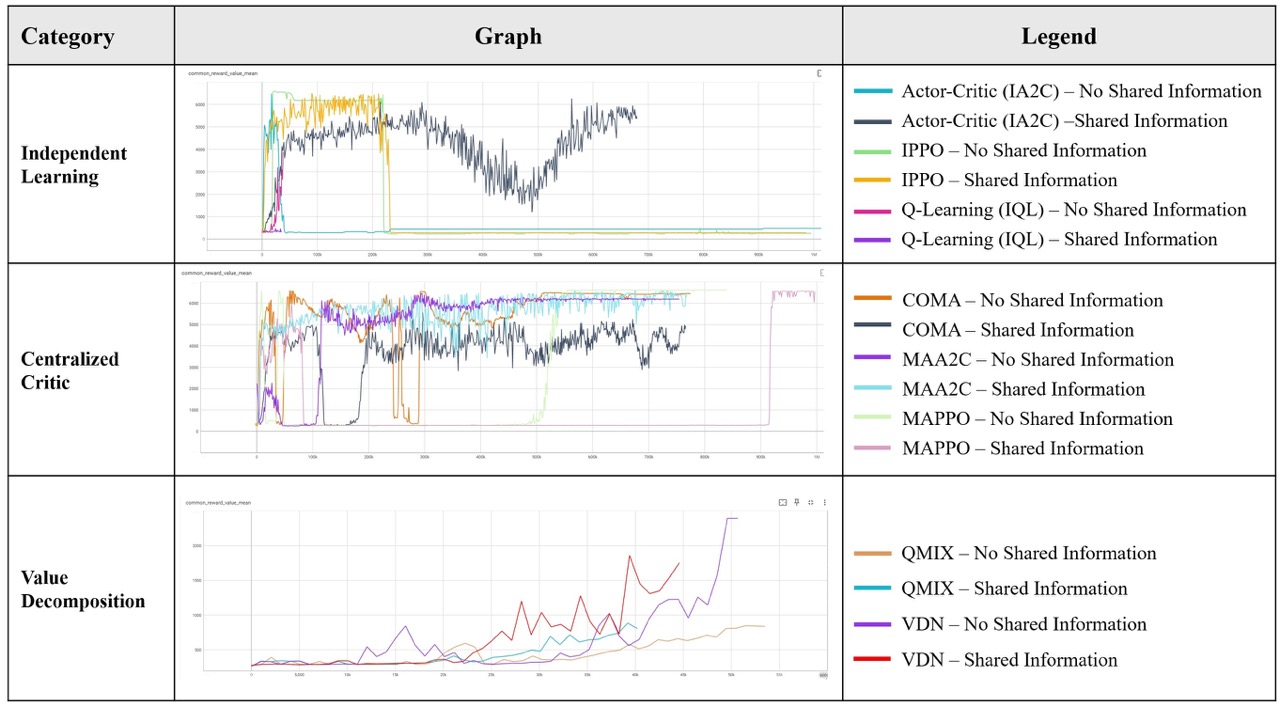
A central challenge in multi-agent systems is that from each agent's perspective, the environment is non-stationary, and the joint state–action space grows combinatorially with the number of agents (Lowe et al., 2017). Traditional optimization techniques, such as mixed-integer programming (MIP), and heuristics including genetic algorithms and simulated annealing, can provide theoretical benchmarks under fixed assumptions but may become computationally prohibitive in large multi-agent settings. In comparison, learning-based approaches offer two key advantages: efficiency, as trained policies enable real-time decision-making without repeatedly solving costly optimization problems, making them suitable for human-in-the-loop applications; and scalability, as GPU-accelerated computation allows these methods to handle larger and more complex environments.
Human-Agent Interplay Interface
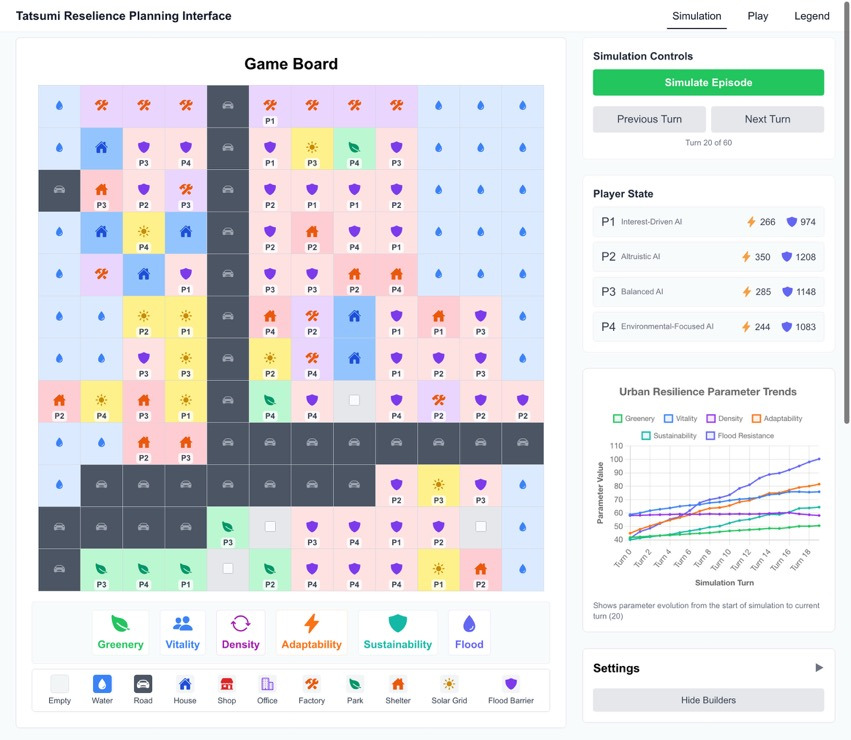
We developed a human-agent interplay interface to allow humans to play with the trained agents. This enables further study of the human-in-the-loop mechanisms. The interface has two modes: simulation and play. In simulation mode, all agents are autonomously controlled by the trained MARL policies. The environment runs until a terminal state is reached, allowing researchers to evaluate emergent behaviors and collective dynamics without human intervention. We observed that increasing the emphasis on self-interest tends to correlate with higher cumulative returns for agents, suggesting that personal and collaborative reward are not in direct conflict. It may also imply insufficient competitive tension that requires further fine-tuning of the game mechanism. In Play mode, the game can be played sequentially, where humans can act as one of the agents by overwriting their actions at each step. This enables human-in-the-loop interactions, which is useful in studying hybrid decision-making, human and agent behaviors, and testing new policies or strategies.
EXPERIMENTS
We conducted three sets of experiments with progressively advancing objectives: first to demonstrate the effectiveness of training, then to evaluate scalability by incorporating resilience factors, and finally to adapt the workflow to a real-world site.
Proof of Concept Experiment
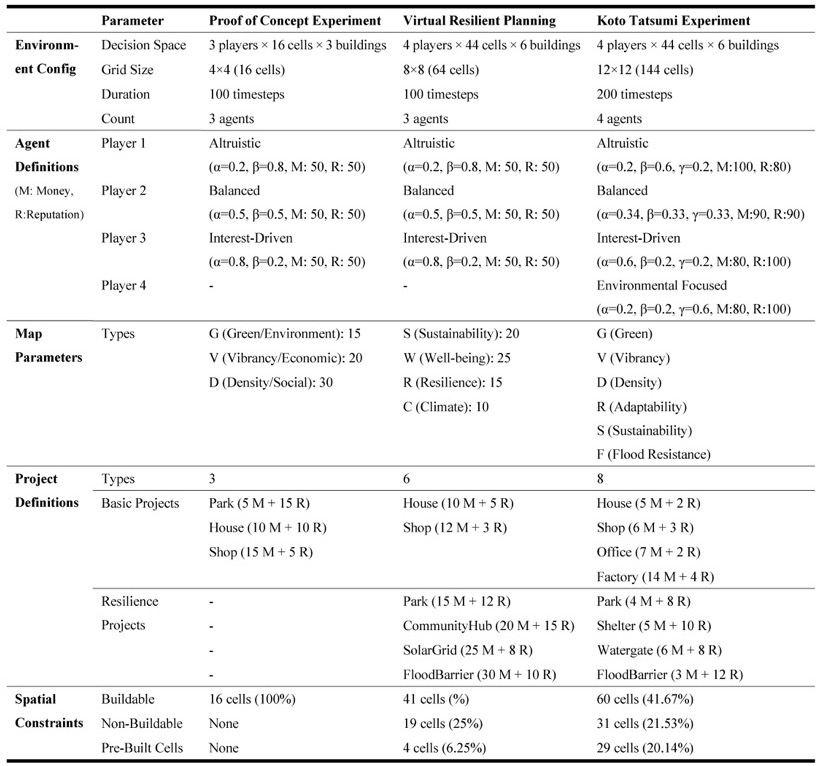
As an initial validation, we designed a minimal-scale experiment to test whether the system can learn optimal strategies in a multi-agent setting. The environment was configured as a 4×4 grid (16 cells) with a limit of 100 timesteps, involving three agents representing distinct stakeholder types: an altruistic player, a balanced player, and an interest-driven player. Each agent started with equal initial resources and pursued their objectives by balancing personal gains with collective outcomes. Players could choose among three building types—Park, House, and Shop. These actions directly affected both the environment indices—Greenery (G), Vitality (V), and Density (D)—and the agents' long-term payoffs, introducing trade-offs between short-term costs and long-term benefits.
To establish the theoretical performance ceiling, we employed large-scale simulated annealing optimization to search for the optimal building placement strategy. We identified the theoretical optimal total episode return to be 8,336 over the 100-timestep horizon. The reinforcement learning agents achieved total episode returns approaching 7,000, demonstrating they successfully learned strategies that capture approximately 84% of the theoretical optimum.
Scaled-up Experiment
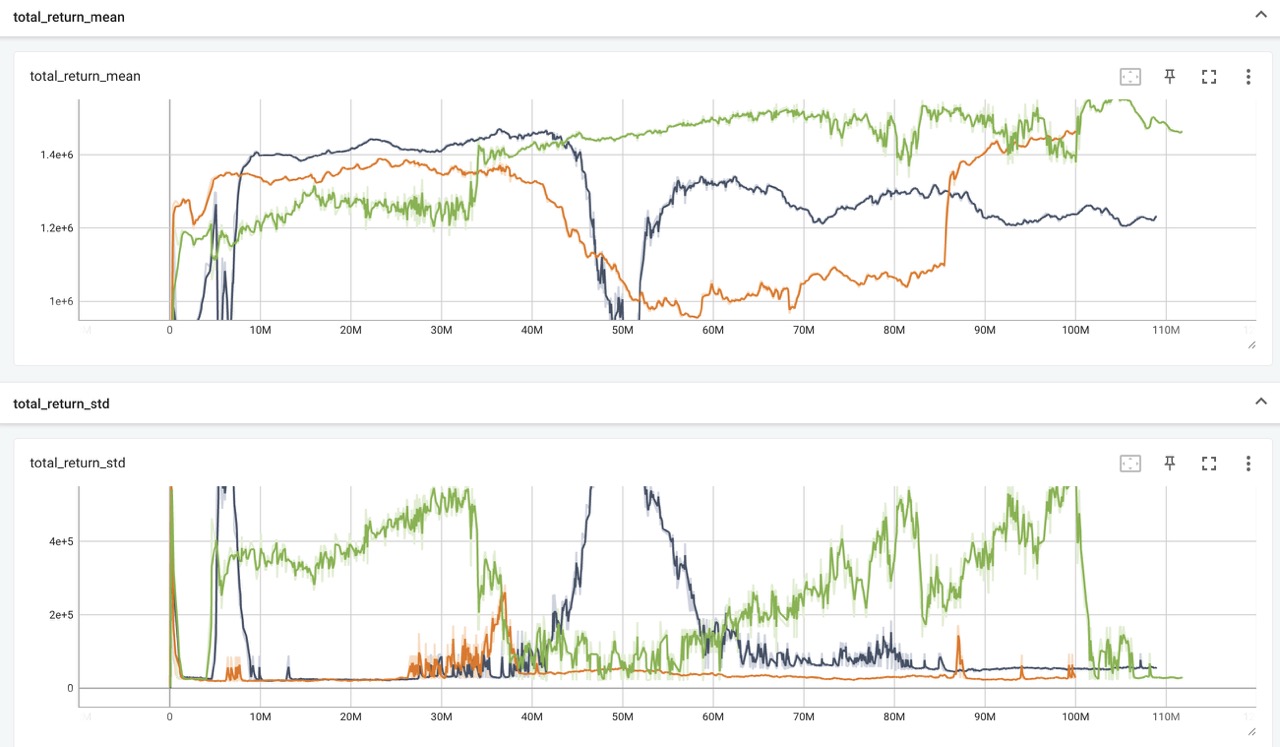
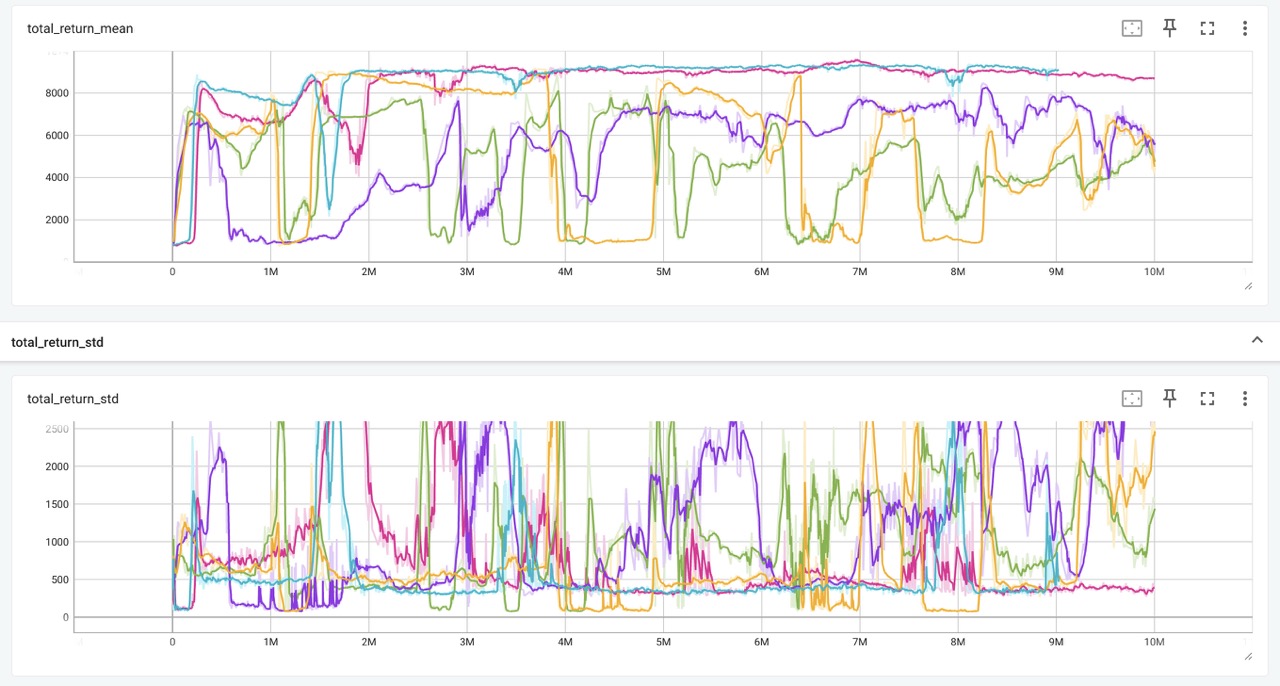
To evaluate collaborative strategies under additional constraints and with resilience as a goal, we doubled the size of the map with an 8×8 grid, adding terrains and pre-built urban infrastructure, simulating the spatial constraints of city planning. We set the training objective to earn maximum cumulative reward under resource constraints, balancing essential demand projects with long-term resilience investments. For this experiment, we conducted five independent training of 10,000,000 episodes with different random seeds.
Despite the instability that built-in multi-agent competition, the overall return generally increases. We observed several inflection points, indicating policy shifts as agents discover new coordination strategies. For some training sessions, the return curve stabilizes near its peak, suggesting convergence to a high-reward collaborative policy. The declining standard deviation further reflects improved policy stability and reduced variance across episodes.
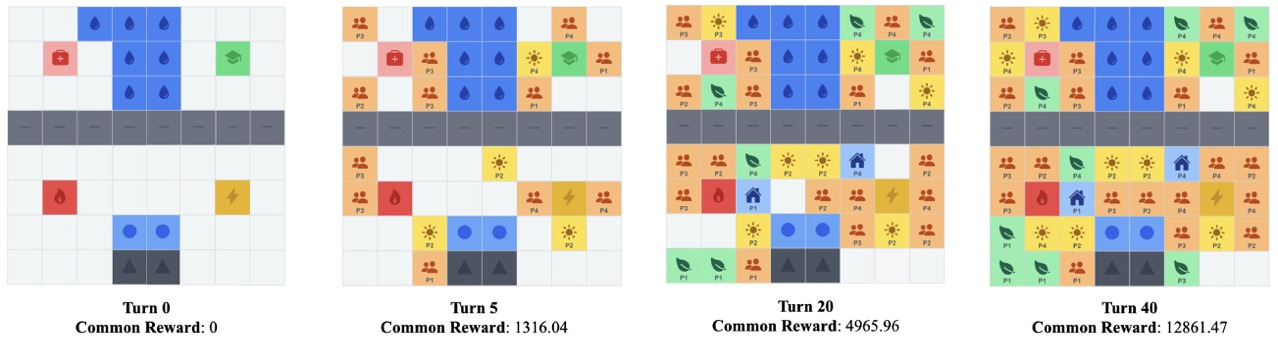
A simulated gameplay session reveals that the trained agents approach urban development under resource constraints, showing a clear emphasis on resilience-oriented projects, such as community hubs, green parks, and solar grids that yield higher long-term rewards, consisting of 82% of the buildable cells. These results reveal that, under dynamic spatial and resource trade-offs, the trained strategies evolve through self-play to internalize spatial–reward relationships between project types and environmental outcomes.
Applied Experiment in Tatsumi, Tokyo
Based on the previous experiments, we extend our model to a real-world site to demonstrate its adaptability and scalability. For this purpose, we selected a district in Koto City, Tokyo. The area is built on low-lying wetlands and frequently exposed to typhoons, making it a critical site to examine the need for resilience improvement historically. However, due to resource constraints, the district requires careful management of resource allocation under stakeholders' preferences.
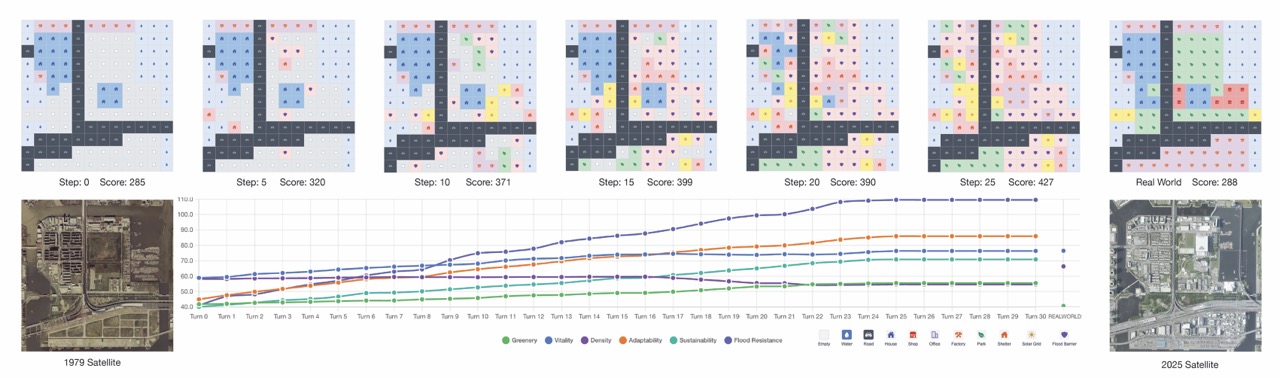
We selected 1980s as the initial period, which marks the beginning of the peak of urban development, and can help us compare simulated results with real-world development results. We initialize the 12×12 grid directly from historical maps: for each cell, we extract the dominant parcel or land-cover feature and assign it to the closest in-game type—either a terrain class or a pre-built project.

A typical simulated game shows the total score increases steadily from the initial 285 points to around 427 points, approximately 49% improvement compared to the baseline score on the 2025 real-world map (288 points). We further observe that resilience-related scores and growth rates gradually surpass those of non-resilience projects, indicating the agents learn to prioritize resilience-oriented investments, which, despite their higher initial costs, yield greater long-term rewards.
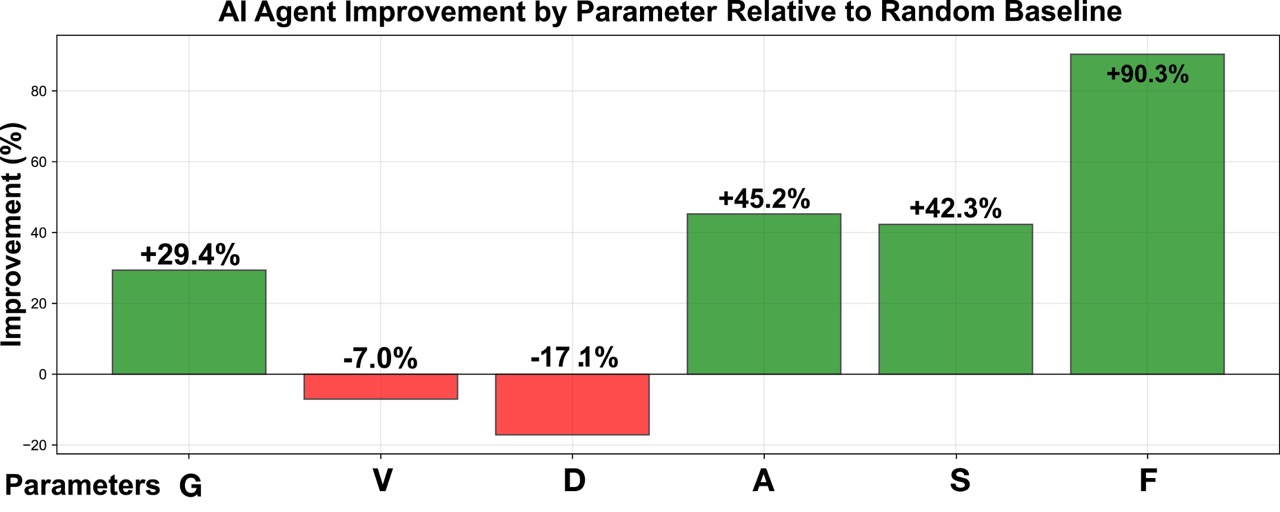
To rigorously assess the impact of our trained agents, we conducted 10,000 independent simulation runs against a random-policy baseline. Compared with the random baseline, the AI agents achieved a higher average total score (452.1, standard deviation (SD) = 3.2 vs. 357.3, SD = 16.0; p < 0.01) and a more concentrated distribution (interquartile range (IQR): 1.82 vs. 21.19). At the parameter level, the agents achieved substantial gains in resilience-related dimensions—Adaptability (A), Sustainability (S), and Flood Resistance (F)—while also improving Greenery (G). These advances indicate that the agents systematically learned to prioritize long-term resilience and adaptability.
CONCLUSION AND FUTURE WORK
This study presents a practical framework for modeling and evaluating the resource allocation process as a trainable digital board game, offering a novel bridge between game theory, multi-agent learning, and participatory planning. We capture the complex trade-offs between individual incentives and collective outcomes to maximize urban resilience through reward design. Notably, our scaled-up simulation shows that trained agents can learn to prioritize resilience-oriented projects while maintaining urban viability through self-play, forming context-aware, adaptive strategies through decentralized competition. The gamified environment serves not only as a learning substrate for agents but also as an interface for public engagement, supporting human-in-the-loop experimentation, which builds a foundation for explainable, interactive simulation with a focus on transforming how urban policy is prototyped and negotiated in future AI-augmented decision-making.
Several limitations remain. First, the reliance on an orthogonal grid restricts the ability to accurately capture irregular urban block structures. Second, the scoring system is based on predefined objective indices, which may oversimplify or misrepresent the nuanced trade-offs inherent in real-world decision-making. Third, reinforcement learning depends heavily on trial-and-error exploration, resulting in low training efficiency and potential instability or convergence challenges when scaling to larger environments and action spaces. More formal equilibrium evaluations are left for future work. Finally, although the framework provides an interactive interface that allows humans to observe and engage with the decision-making process, it has not yet incorporated full-scale human participant studies.
Looking ahead, future work will focus on scaling the environment and agent population to build a more robust pipeline under more complex and realistic conditions. Another direction is to integrate large language models to support human-interpretable reasoning processes and comprehensive chains of thought, incorporating real-life common sense and its influence on complex decision-making issues. Last but not least, the framework will be applied to real-world planning scenarios with human participants to explore its applicability in an AI-driven, participatory design process.